Building a ‘Text to SQL’ fine-tuning dataset for ‘AI that makes it easy for marketers to write SQL’

Customer K is,
A leading domestic credit card company that offers credit cards, debit cards, and a wide range of financial services. Through diverse partnerships and digital payment platforms, K provides personalized financial services tailored to customers’ daily lives.
Project Overview
K frequently leverages its internal databases for marketing purposes such as increasing card usage and planning merchant campaigns. However, marketers found it difficult to write SQL queries themselves, which lowered data accessibility and slowed down decision-making.
To solve this problem, K sought to develop an AI solution that would allow marketers to query data instantly through natural language. Yet, the large language model (LLM) they planned to adopt faced several limitations:
- Traditional machine learning approaches require exact matches of column names, which limits real-world usability.
- To improve natural language understanding, the model needed a wide variety of query expressions.
- Without domain-specific knowledge of table joins and data context, accuracy improvements were difficult.
Therefore, K needed a fine-tuned Text-to-SQL dataset—and chose Crowdworks as its partner.
Why Client K Chose Crowdworks
- Proven expertise in building advanced datasets optimized for real-world environments
- Access to professionals with practical SQL query experience
- Consulting capabilities built on deep understanding of complex data structures and domain context
- On-site collaboration that enabled real-time integration with the client’s systems
Project Solution Process
1) Build 8,400 Natural Language–SQL Query Pairs
In the first stage, Crowdworks focused on K’s top 80 most frequently used tables. We created 8,400 natural language queries paired with corresponding SQL statements. To enhance model robustness, we provided multiple SQL variations for each natural language expression, ensuring both diversity and generalization in training. We also varied sentence tone, structure, and word choice to simulate real usage scenarios, while explicitly documenting table and column names for data integrity.
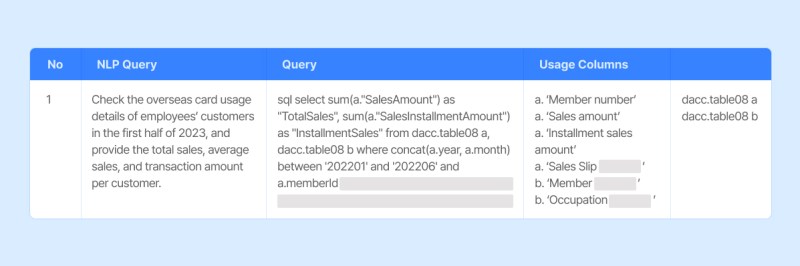
Example of Building NL Query and SQL Pair Data
2) Metadata Designed Around K’s Marketing Needs
In the second phase of the project, we built structured metadata at the table and column level to improve SQL generation accuracy based on the results of the first phase. For approximately 80 frequently used tables in K’s system, we documented detailed, context-driven information such as table definitions, Korean table names, types of queryable data, and possible join relationships with other tables. This created a reference dataset that enabled the model to interpret natural language queries and generate appropriate SQL statements. Importantly, this stage went beyond simple data definitions. By incorporating a deep understanding of K’s marketing objectives and data flows, we developed explanation-centered data that significantly enhanced overall completeness and quality.
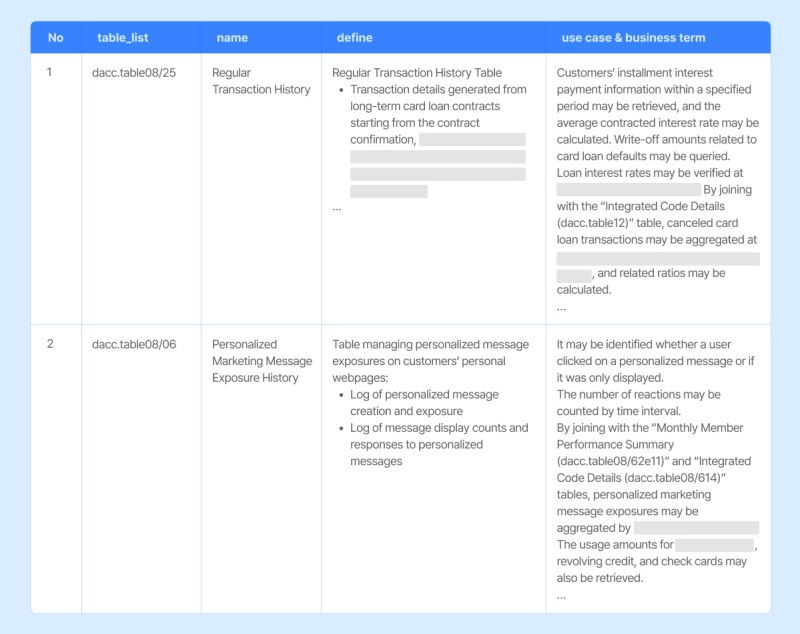
Example of Reference Guide Data Construction
3) Deploying Selected SQL Experts On-Site
Because this project required access to sensitive internal databases, Crowdworks provided an on-site collaboration model with SQL experts. Only data workers with over two years of hands-on SQL experience were selected through in-person interviews and coding tests. This ensured they could identify primary tables, key columns, and manage join complexity.
To minimize disruptions, the same workers from phase one continued into phase two, eliminating onboarding delays and enabling seamless progress. A dedicated PM first analyzed existing SQL queries within K’s system to create tailored guidelines. Continuous feedback loops with the client ensured rapid iteration and high-quality results.
Project Outcomes
We secured more than twice the amount of data originally agreed upon with the client in a short period of time, and were able to deliver high-quality data that satisfied both the diversity and accuracy of natural language query patterns. Highly satisfied with the results, Client K is planning to collaborate further with Crowdworks in its 2025 projects.
- Testimonial from the PM
“At the start, there were concerns about whether natural language to SQL automation could truly match marketers’ real needs. K’s internal data structures were complex, and non-technical marketers were the main users. But once our specialists were deployed on-site, we worked closely with the client to design data structures optimized for business goals and categorize queries by marketing use cases. Those initial concerns quickly gave way to trust.Concerns quickly turned into trust.
In the end, the client received over twice the expected deliverables and gained a dataset centered on real-world usability. They told us, ‘We want to continue working with Crowdworks in next year’s projects.’ For me as a PM, it was meaningful to not only deliver the dataset but also propose solutions rooted in business understanding.”
When building specialized or high-complexity datasets, the most critical factors are extensive project experience and expertise, the right solutions, and the careful selection and management of skilled data workers. If you are looking for a systematic approach to LLM dataset construction, Crowdworks is here to help!